elasticsearch倒排索引理解
首先了解一下什么正排索引:
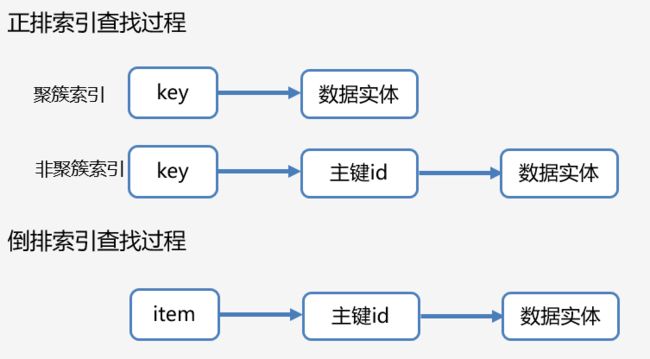
正排索引
1、拿Mysql Innodb的聚簇索引来说,每个索引其实都是一颗 B+ 树,主键索引称作聚簇索引,其他非主键索引称作二级索引,每个表中每一行的记录值都完整的保存在主键索引的叶子节点上,二级索引的叶子节点保存的是主键的值。
2、非聚簇索引只是叶子节点的内容存放的是该表的主键信息,查询的顺序则是 先通过非聚簇索引的字段找到叶子节点中一致的 单个或者多个主键id,再使用这些主键id进行回表,最终获得对应的完整实体数据。详细可看mysql B+树(btree)索引原理。
倒排索引
创建倒排索引的field,会通过IKAnalyzer(比较流行的中文分词器)根据语义将字段中的field分成一个一个对应的词索引(term index),构成该类型数据的全部词索引集合(term dictionary),如“ "text": "喜欢篮球、英雄联盟" ”会被分成 (喜欢、篮球、英雄、联盟)4个term index;第二列是含有这些term index对应的文档Id(documentId),这个数据可以帮助我们最终溯源到完整实体数据;第三列则是对应term index在该文档字段中的位置,0表示在开头的位置,这个可以帮助标注检索出来数据的高亮信息。
| term dictionary | documentId | position |
|---|---|---|
| 喜欢 | 1,5,10 | 0,2,5 |
| 篮球 | 1,2,33 | 1,5,6 |
| ... | ... | .. |
分词
如何输入一个文档数据后创建对应的倒排索引,如 {“id”:1,“name”:“小明”,“hobby”:“喜欢篮球、英雄联盟”}
插入文档时,将text类型的字段做分词然后插入倒排索引,此时就可能用到analyzer指定的分词器, 这里我们对hobby这个字段分词(喜欢、篮球、英雄、联盟)会被分成多个对应的词索引(term index),每个term index对应的位置、文档id也都会生成,添加到上述的数据结构索引库中。

- latest comments
- 总共0条评论
最新评论